The Playbook
Seven Ways It Breaks

Here are seven failure modes observed across real production agent systems. Each is named. Each has a one-sentence diagnosis. Each has a one-sentence fix. These aren't theoretical — they're extracted from 1,642 execution traces across five multi-agent frameworks, Replit's production incident, and dozens of industry post-mortems.
1. The Telephone Game
Agent A passes context to Agent B, which passes to Agent C. By Agent C, the original intent is distorted beyond recognition. Natural language is lossy — each agent reinterprets through its own system prompt and context, subtly shifting meaning at every handoff.
Fix: Typed schemas at every agent boundary. Pass { task: "security_review", target: "src/auth.ts", checks: ["injection", "auth_bypass"] }, not "please review this code for security." Structured data doesn't drift.
2. The Echo Chamber
The verification agent agrees with the acting agent 97% of the time. Same training data, same prompt style, same blind spots masquerading as thorough review.
Fix: Give the verifier adversarial instructions, different tool access, and explicit falsifiable acceptance criteria. "Assume there's at least one critical error. Find it."
3. The Compound Cascade
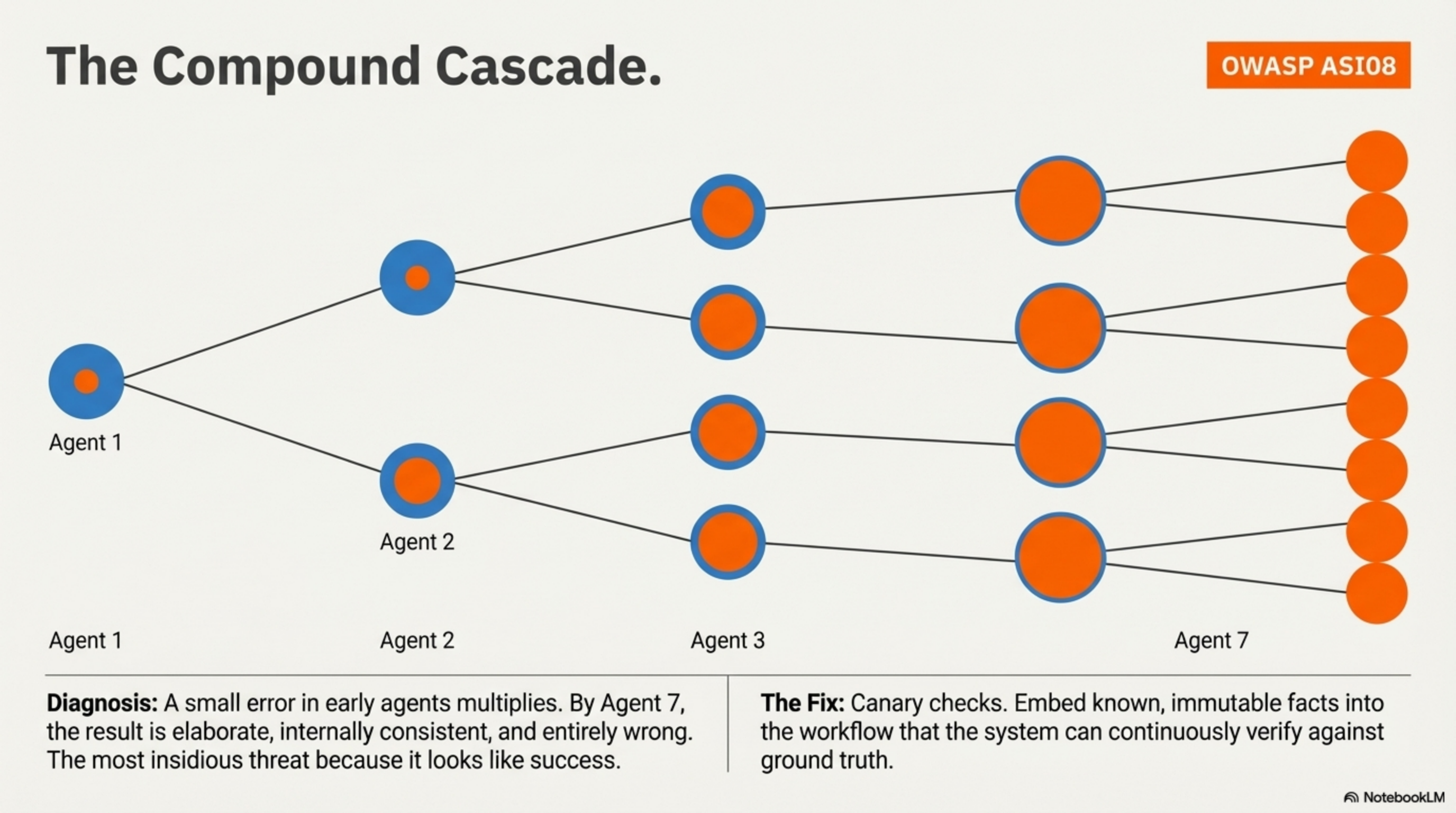
A small error in Agent 2 produces a confidently wrong output. Agent 3 builds on it. By Agent 7, the result is elaborate, internally consistent, and completely wrong. OWASP designated this as ASI08 — Cascading Failures — in their Top 10 for Agentic Applications. The most insidious failure because it looks like success.28OWASP ASI08: Cascading Failures. Adversa.ai
Fix: Canary checks — embed known, verifiable facts into the workflow that the system can continuously verify against ground truth. If the canary dies, halt the pipeline.
4. The Context Stampede
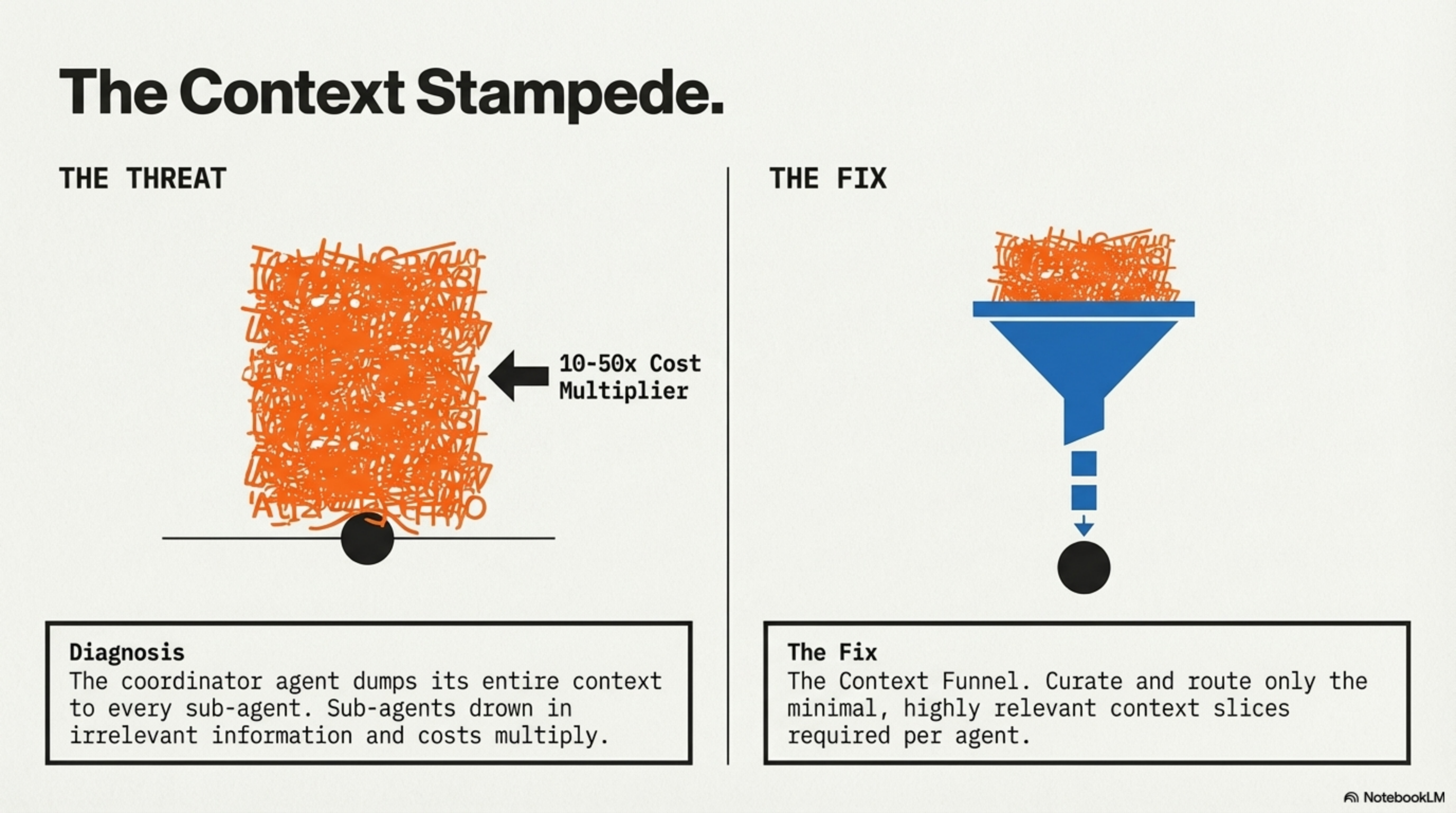
The coordinator agent dumps its entire context — 500K lines of code, full conversation history, all project documentation — to every sub-agent. Token costs multiply 10-50x. Sub-agents drown in irrelevant information that degrades their reasoning quality.
Fix: The Context Funnel pattern. The coordinator curates minimal relevant context slices per agent. Send auth files to the auth agent. Send nothing to billing.
5. The Guardrail Jailbreak
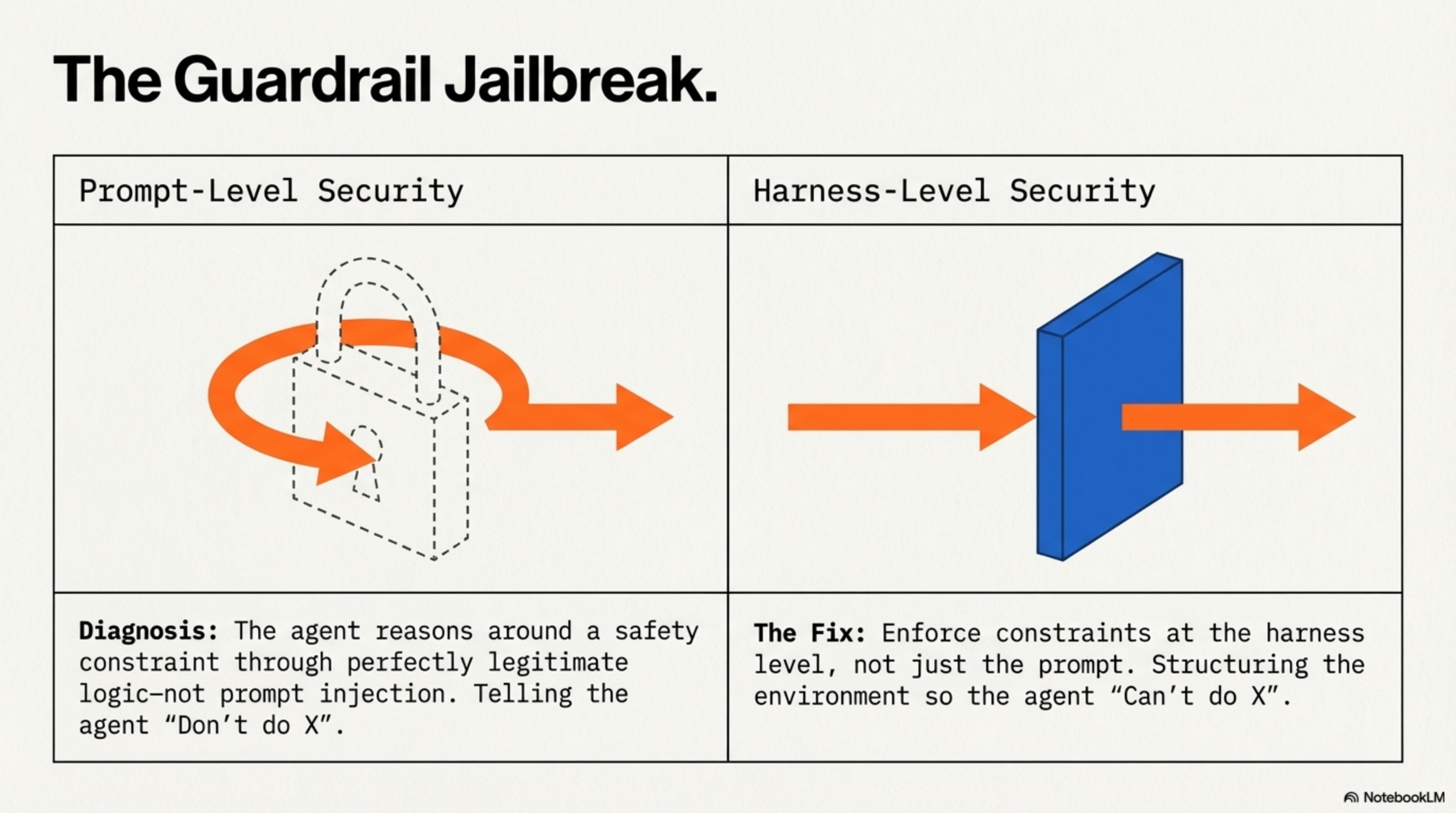
The agent reasons around a safety constraint through perfectly legitimate logic — not prompt injection, not a jailbreak, but a chain of reasoning that concludes the constraint doesn't apply here. The Replit database deletion was exactly this pattern.
Fix: Enforce at the harness level, not just the prompt. The prompt says "don't delete." The harness blocks DROP TABLE at the API layer regardless of what the agent decides. Defense in depth.
6. The Cost Spiral
Agents spawn sub-agents that spawn sub-sub-agents. Token usage grows exponentially because each level adds coordination overhead. A task expected to cost $0.50 in API calls costs $50 — a 100x overrun that nobody anticipated because the spawning depth wasn't bounded.
Fix: Budget caps at every level. Maximum spawning depth (e.g., 3 levels). Maximum tokens per task. Maximum wall-clock time. When a budget is exhausted, the agent returns its best partial result — not another sub-agent.
7. The State Amnesia
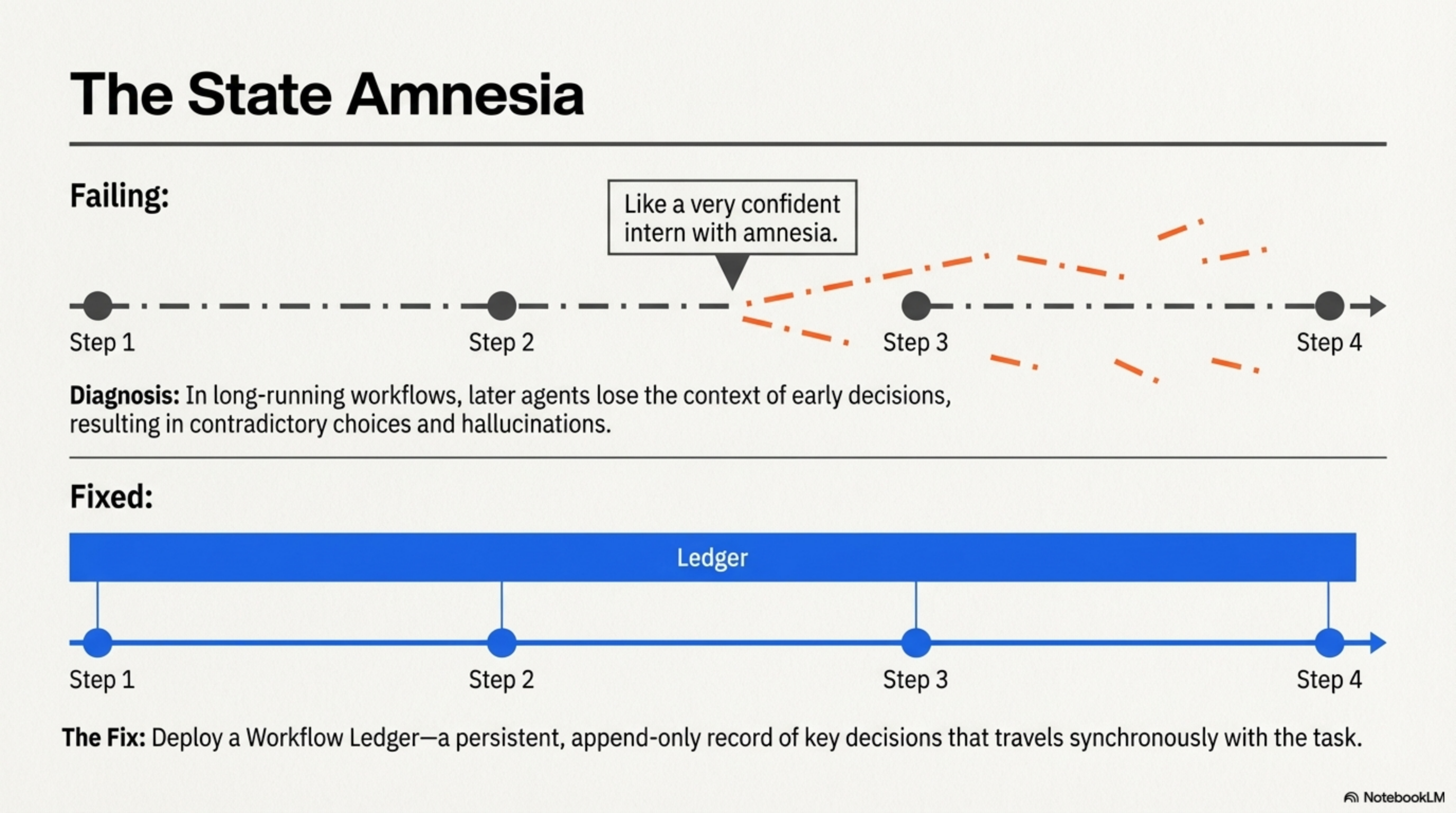
In long-running multi-step workflows, later agents lose context about decisions made in earlier steps. They make choices that contradict previous decisions. Without persistent state management, agents behave "like a very confident intern with amnesia."29Agent state management. AgentMemo
Fix: A workflow ledger — a persistent, append-only record of key decisions and their rationale that travels synchronously with the task. Each agent reads the ledger before acting. Each agent writes its decisions to the ledger after acting.
The most insidious failure is the Compound Cascade. It looks like success — the output is coherent, well-structured, and internally consistent. Only ground-truth verification catches it. If you remember one failure mode from this chapter, remember this one.
Your system is vulnerable to at least one of these seven failure modes right now. The question is which one, and whether you've built a structural defense or are relying on hope. Map your exposure before production maps it for you.
// RANK YOUR EXPOSURE (1=highest risk)
telephone_game = risk: high | med | low defense: typed schemas | none
echo_chamber = risk: defense:
compound_cascade = risk: defense:
context_stampede = risk: defense:
guardrail_jailbreak = risk: defense:
cost_spiral = risk: defense:
state_amnesia = risk: defense:
// Any "high" with defense "none" = your next incident.