The AGENT Principles
Five Letters
In 2000, Robert C. Martin published five principles for object-oriented design. Single Responsibility. Open/Closed. Liskov Substitution. Interface Segregation. Dependency Inversion. Someone later noticed the initials spelled SOLID, and the acronym stuck. Twenty-six years later, SOLID is still taught in every computer science program on earth.
Agent composition needs its equivalent. Five principles — one for each letter in AGENT — that address the specific challenges of composing autonomous, probabilistic entities.

A — Autonomy Boundaries
Define what an agent CAN do before defining what it SHOULD do.
With functions, you define what they do — and they can't do anything else. With agents, you define what they're allowed to do — because they can do anything within their capability. Every permission you grant is attack surface for unexpected behavior. Start with the minimum set. Expand only when you hit a specific, documented limitation. OWASP calls this "Least Agency."25OWASP "Least Agency" + AWS Generative AI Lens. AWS Docs
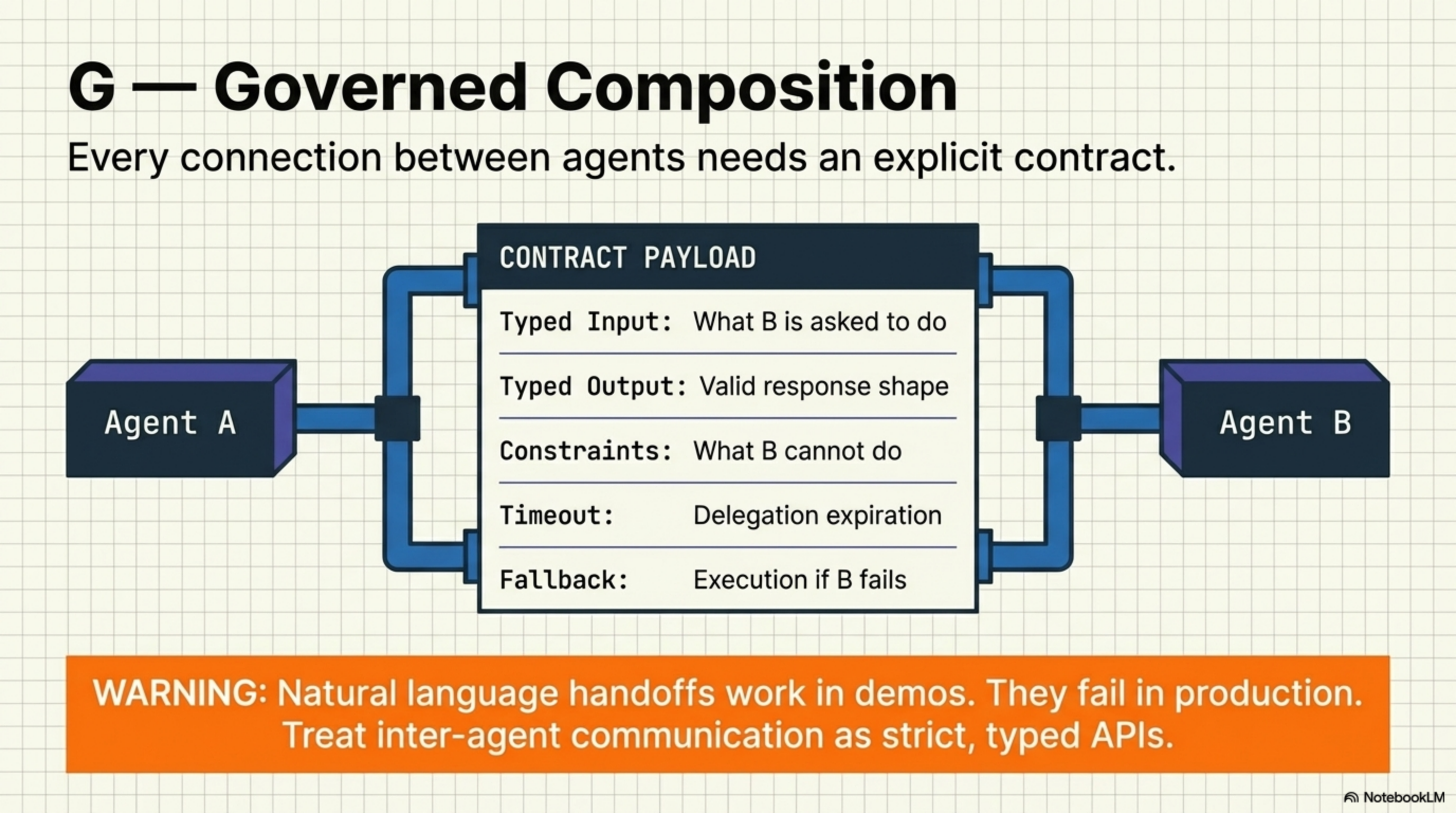
G — Governed Composition
Every connection between agents needs an explicit, typed contract.
When Agent A delegates to Agent B, the delegation must include: what B is asked to do (typed input schema), what a valid response looks like (typed output schema), what B cannot do (constraints), when the delegation expires (timeout), and what happens if B fails (fallback strategy). Natural language handoffs between agents work in demos. They fail in production.
E — Explicit Observability
If you can't see what an agent did and why, you don't have a system. You have a hope.
Every agent interaction produces a trajectory log — inputs, tool calls, reasoning chains, outputs, timestamps, token costs. Don't just log inputs and outputs. The middle is where bugs live. An agent that produces the right output for the wrong reason will produce the wrong output for a slightly different input — and you won't know why unless you logged the reasoning.26"Agent Tracing for Debugging Multi-Agent Systems." Maxim AI
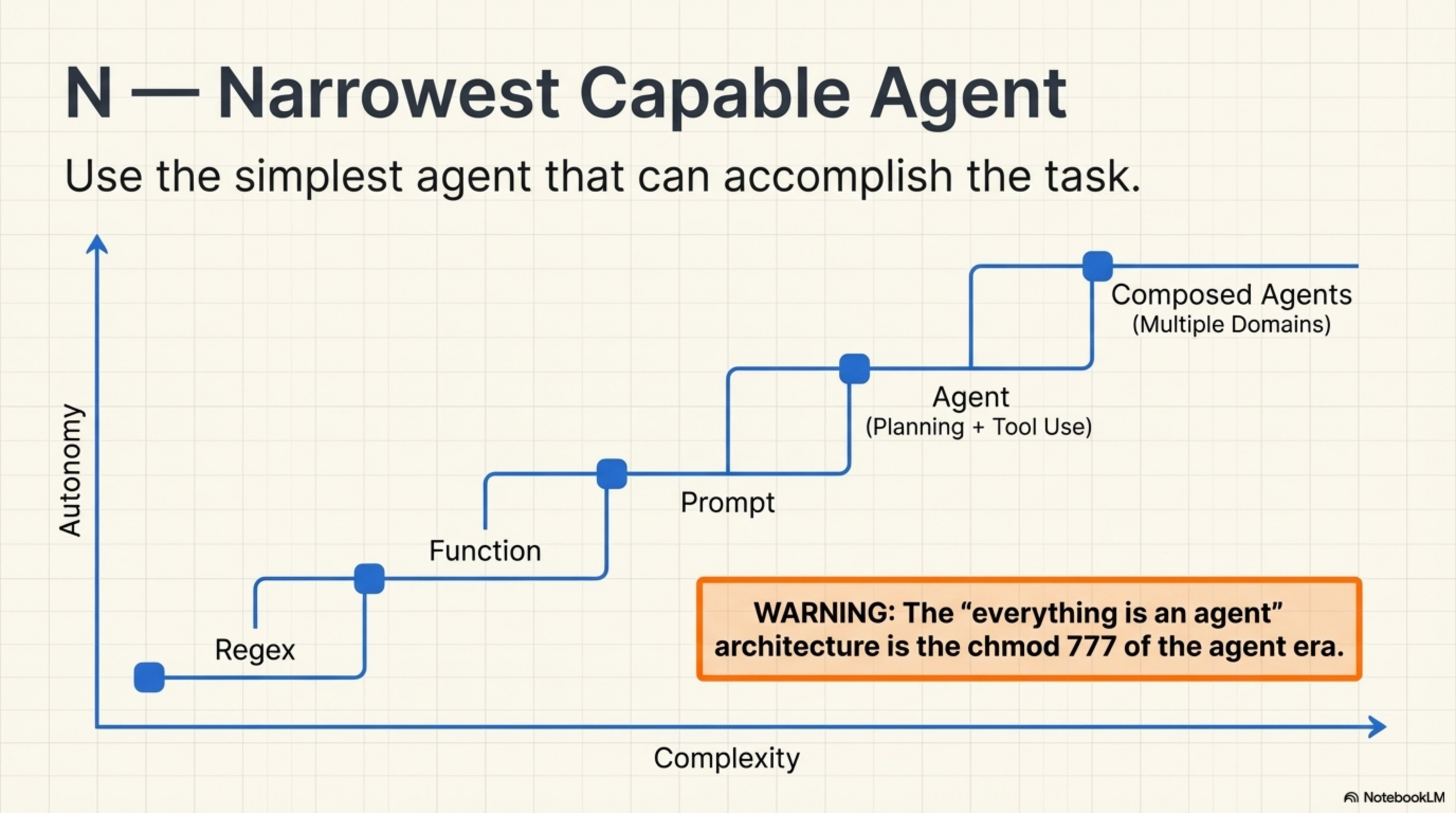
N — Narrowest Capable Agent
Use the simplest agent that can accomplish the task.
Can a regex do this? Use a regex. Can a deterministic function? Use a function. Can a single LLM call without tools? Use a prompt. Does it need planning, tool use, and multi-step reasoning? Now use an agent. Does it need multiple domains of expertise? Now compose agents. The "everything is an agent" architecture is the chmod 777 of the agent era.
T — Trajectory-Driven Improvement
Every failure is training data. Every success is a benchmark.
Agent systems don't improve through code changes the way traditional software does. They improve through trajectory analysis. When something fails, you analyze the trajectory: what did the agent see, what did it decide, where did the decision diverge from intent? This feeds back into better prompts, better tool schemas, better governance rules, and better evaluation datasets. The flywheel: more agents → more trajectories → better governance → more reliable agents.27Phil Schmid: "Every failure can be used for training the next iteration." philschmid.de

Run this against your current agent architecture before your next sprint planning. Each principle addresses a specific failure mode. Each "false" is a structural risk that will surface in production — the only question is when.
// AUDIT EACH PRINCIPLE
A autonomy_boundaries_defined = true | false
G typed_contracts_at_every_boundary = true | false
E full_trajectory_capture = true | false
N simplest_capable_agent_per_task = true | false
T systematic_trajectory_learning = true | false
// Count of false: your structural risk score.
// 0 = production-grade. 3+ = demo-grade.