Five More Patterns
The Specialist Ensemble and Verification Loop are the two patterns you'll use most often. But five more show up repeatedly in production agent systems. Each gets a name, a one-line description, a story, and a template you can use on Monday morning.
3. The Skill Mesh
OpenClaw's public registry — ClawHub — hosts 13,729 skills as of February 2026. Agents discover these skills at runtime. They don't know in advance which capabilities exist. They search the registry, find matching skills by semantic similarity, and compose them dynamically. Like a developer discovering npm packages — except the consumer is another piece of software, not a human.23ClawHub: 13,729 skills. clawhub.ai
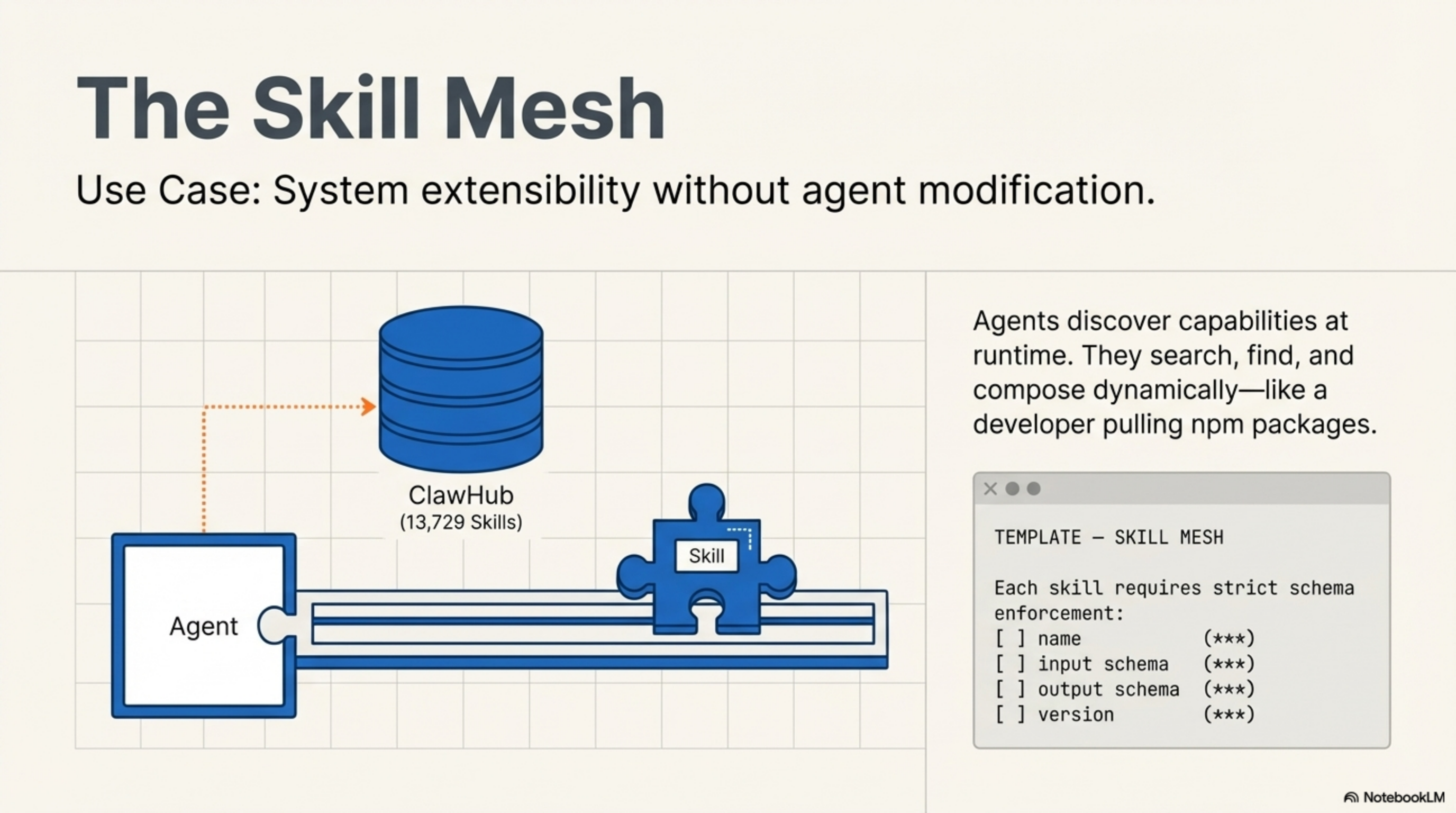
Use when: you want an extensible system where new capabilities are addable without modifying existing agents or redeploying infrastructure.
4. The Escalation Chain
Think of a hospital emergency room. The triage nurse handles what she can — vital signs, initial assessment, minor treatments. What she can't handle goes to the ER doctor. What the doctor can't handle goes to the specialist on call. Each level is slower and more expensive. You only escalate when necessary.
The same pattern applies to agents. Start with the cheapest, fastest model — Haiku for simple tasks. If it can't handle the complexity or its confidence is below threshold, escalate to Sonnet. If Sonnet fails, escalate to Opus. If Opus flags uncertainty, escalate to a human.
Use when: task complexity varies widely across your workflow and you want to optimize for cost without sacrificing quality on hard problems.
5. The Context Funnel
Your codebase is 500,000 lines of TypeScript across 2,000 files. Your task is "add rate limiting to the API layer." A coordinator agent holds the big picture — the project structure, the architecture diagram, the requirements — and sends each specialist agent only the context it needs.
The auth specialist gets the auth middleware files. The API specialist gets the route handlers. The billing specialist gets nothing — rate limiting doesn't affect billing. Sending the entire 500K-line codebase to every sub-agent would cost 10-50x more in tokens and drown each agent in irrelevant information that degrades its reasoning.
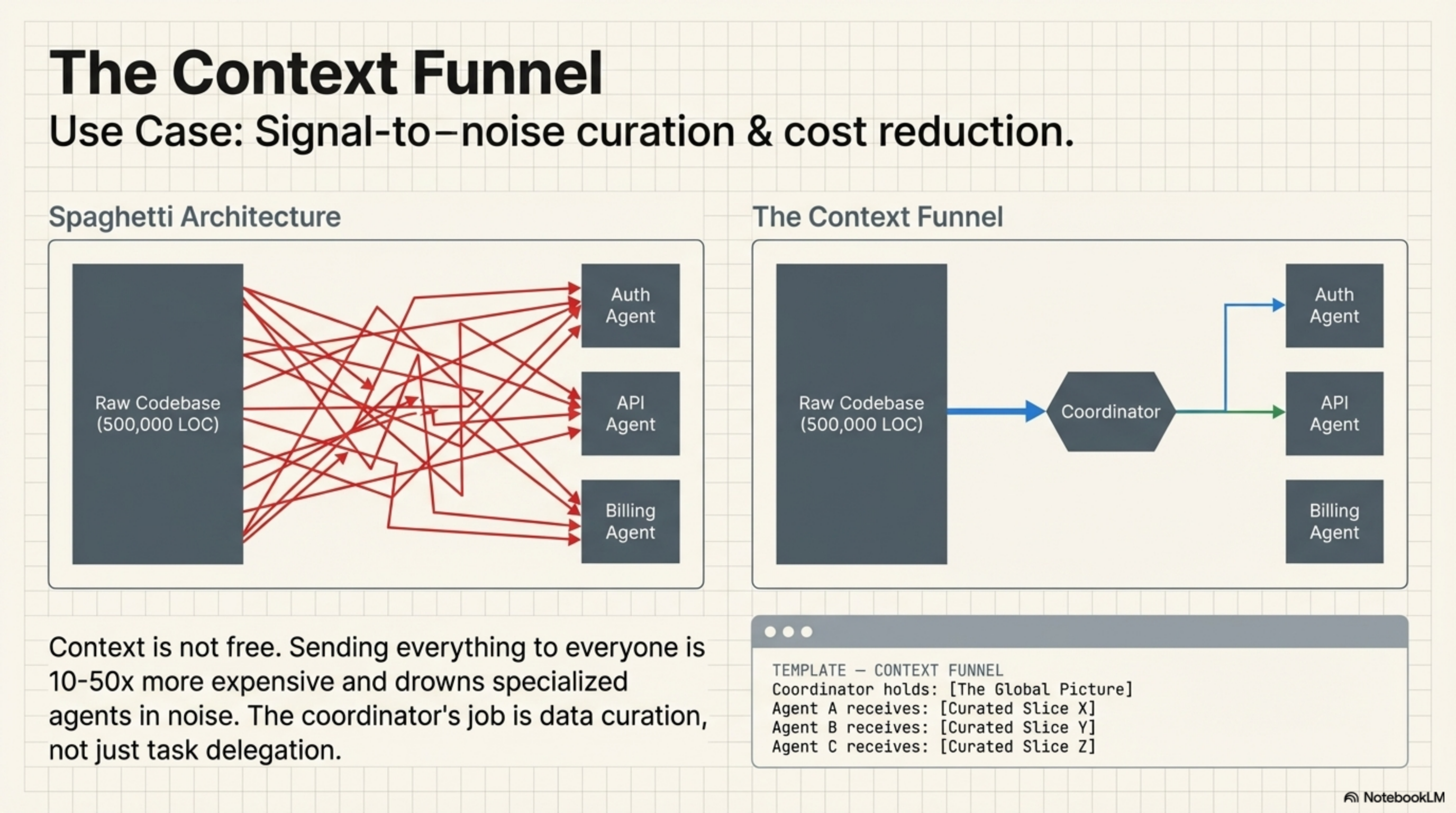
Use when: full context exceeds a single agent's effective capacity or is prohibitively expensive to pass to every sub-agent.24"AI Agent Handoff: Why Context Breaks." XTrace
6. The Consensus Protocol
For high-stakes decisions — deploying to production, approving a financial transaction, modifying security-critical code — you need more confidence than a single agent provides. Run three agents independently on the same task. Compare their outputs. Proceed only when they agree. Escalate to human review when they disagree.
This is expensive — 3x the compute. Use it only when the cost of a mistake exceeds the cost of triple-checking.
7. The Trajectory Replay
Something went wrong in your agent pipeline. You need to understand why — not just what the output was, but the sequence of reasoning, tool calls, and decisions that produced it.
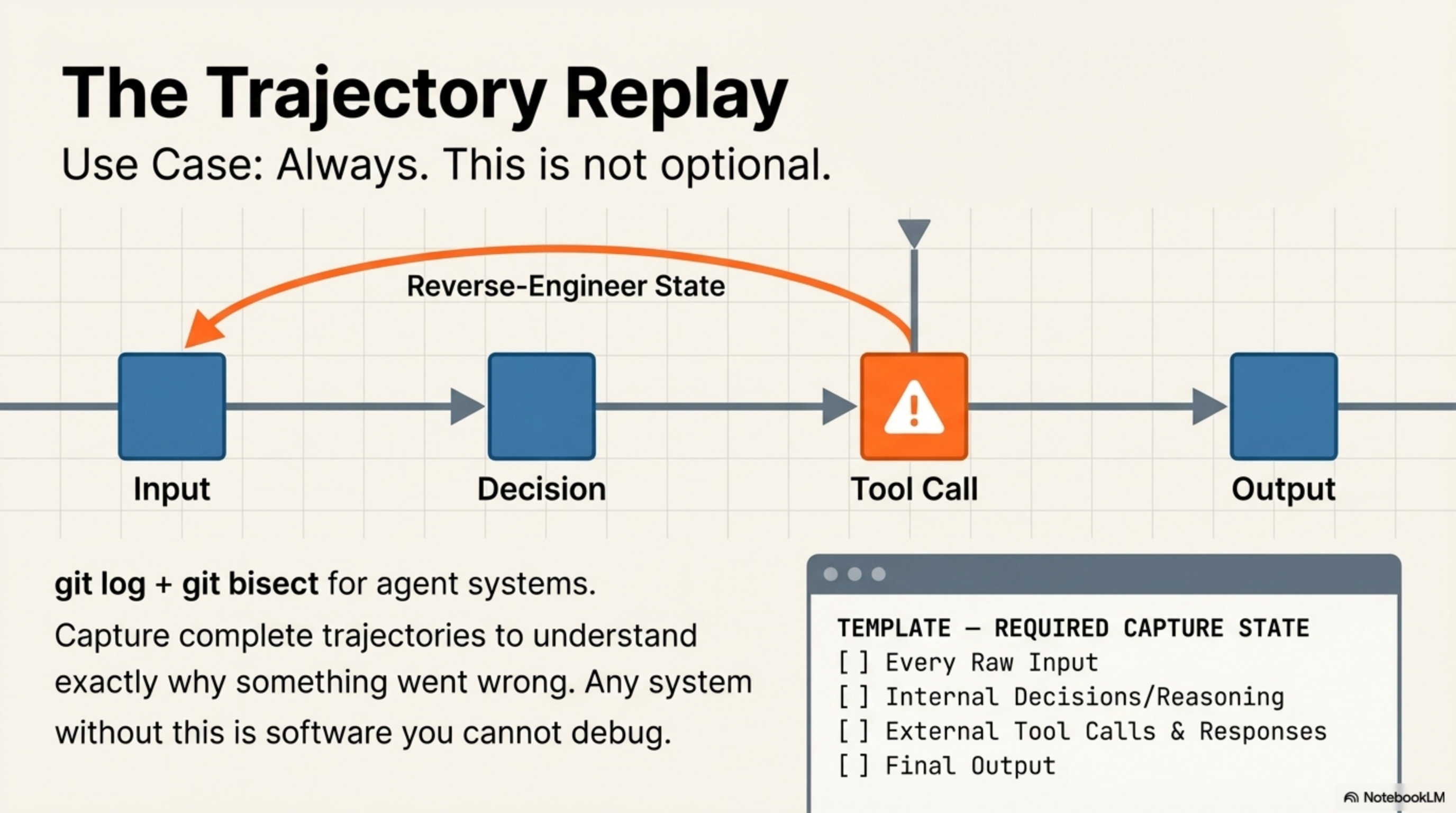
Capture complete trajectories — every input, every decision, every tool call with arguments and results, every output. Build tooling to replay them step by step, the way you'd replay a flight data recorder after an incident. This is git log + git bisect for agent systems.
Use when: always. This is not a pattern you choose to apply. It's infrastructure you must have. Any agent system without trajectory replay is software you cannot debug.