The Verification Loop

A startup in San Francisco deployed a code-review agent in early 2025. The agent read pull requests, analyzed the diffs, identified potential bugs and security issues, and left detailed comments — just like a senior engineer would during code review. The team loved it. Code review turnaround dropped from two days to two minutes.
After a month, they measured. The verification agent agreed with the code-writing agent 97% of the time. In thirty days, across hundreds of pull requests, it almost never flagged a bug that the writing agent had introduced.
The problem was obvious in hindsight. Both agents used the same underlying model (Claude 3.5 Sonnet). Both received similar system prompts ("review this code for quality and security"). Both operated on the same context (the PR diff plus the surrounding codebase). They had the same training data, the same reasoning patterns, the same blind spots. The "reviewer" was just the "writer" wearing a different hat.
Then a senior engineer on the team changed one thing: the verifier's system prompt. Instead of "review this code for security issues," she wrote:
"You are a hostile security researcher conducting a paid penetration test. Your professional reputation depends on finding vulnerabilities others missed. Assume this code contains at least one critical security flaw. Your job is to find it. If you find nothing, you've failed."
The catch rate doubled.

Why different biases matter
The Israeli military uses a practice called the "10th Man" doctrine. When nine intelligence analysts agree on an assessment — the threat is low, the border is secure, the situation is stable — the designated tenth analyst must disagree. Their job is to investigate alternative scenarios, challenge assumptions, and argue the opposite case. Not because the nine are wrong, but because groupthink creates blind spots that are invisible from inside the group.22Israeli "10th Man" doctrine. AI red teaming research. HackTheBox
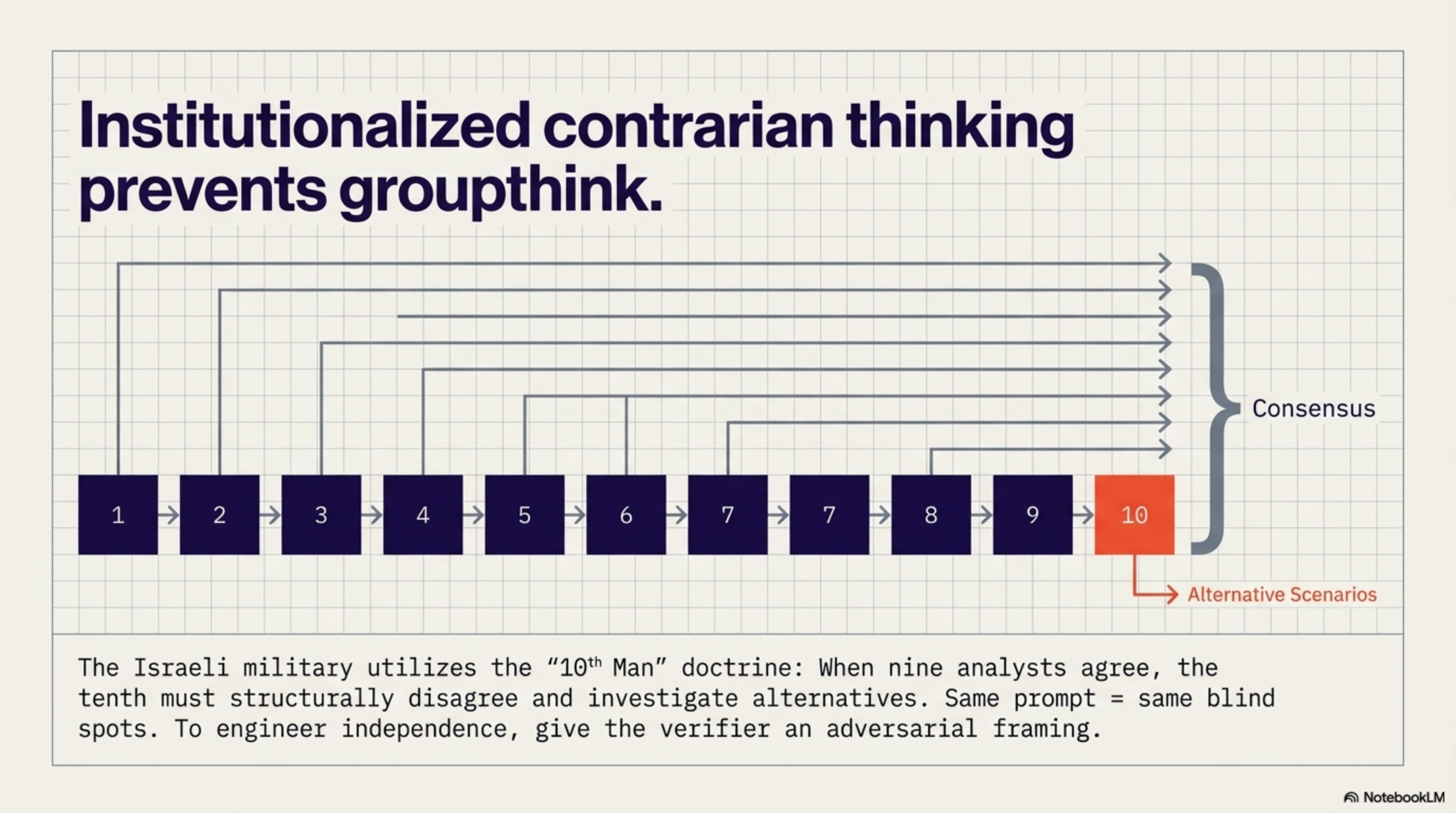
The same principle applies to agent verification. Same prompt = same blind spots. Same model = same reasoning patterns. Same context = same attention distribution. To catch errors that the acting agent can't see, the verifier must be structurally independent — different prompt framing, different tool access, different success criteria.
What "verify" means: not "looks good." Verification means specific, measurable, falsifiable criteria. "All tests pass. No new security warnings in the SAST scan. Diff is under 200 lines. Output matches the typed contract schema." If the criteria aren't falsifiable, the verification is theater.
My verifier has different: