Composing Probabilities
Water at 99 degrees is hot water. Water at 100 degrees is steam. One degree. Different state of matter.
The jump from services to agents looks like one more step on the staircase. It isn't. It's a change of state.

Here's why. Meet Kenji Watanabe, a platform engineer at a mid-stage fintech company in Tokyo. In February 2026, Kenji integrated an AI code-review agent into his team's CI pipeline. The agent reviewed pull requests automatically — scanning diffs, flagging vulnerabilities, leaving inline comments. His team's review turnaround dropped from 48 hours to 90 seconds. Then Kenji noticed something that changed how he thought about agents.
He had a pull request — 200 lines of Python — that added a new API endpoint. He asked the agent to review it for security issues.
Run it Monday morning. The agent scans the code, identifies an SQL injection vulnerability in the query builder, and writes a clear, accurate report with the exact line number and a fix.
Run it Monday afternoon. Same code. Same prompt. Same model. Same temperature setting. The agent finds the SQL injection again — and flags a timing attack in the authentication check that nobody on your team had considered. A genuinely useful insight that wasn't there four hours ago.
Run it Tuesday. Same everything. The agent misses the SQL injection entirely. Instead, it produces an unsolicited three-paragraph analysis of the authentication flow's session management — thoughtful, well-structured, and completely unrelated to what you asked for.
Three runs. Three different outputs. Same input.
This is not a deficiency in the current generation of models that OpenAI or Anthropic will fix next quarter. This is the nature of probabilistic computation. Large language models generate output by sampling from probability distributions over tokens. Even setting the temperature parameter to zero — which theoretically should make output deterministic — doesn't eliminate variation, because GPU floating-point operations and batch processing introduce irreducible randomness at the hardware level.6"Defeating Non-Determinism in LLMs." FlowHunt, 2025.
The math that changes everything
Every unit of composition before agents was deterministic. Call sort([3,1,2]) and you get [1,2,3]. Every time. On every machine. In every timezone. The output is a guarantee.
Agents are probabilistic. Their output is not a guarantee — it's a distribution. They succeed on a spectrum: sometimes brilliantly, sometimes adequately, sometimes catastrophically. And when you compose probabilistic units into a pipeline, the spectrum doesn't average out. It compounds.
Read that last data point again. Ten agents. Each one 85% reliable — which sounds excellent. The pipeline succeeds one time in five.
You might be thinking: if composing agents is this unreliable, just don't compose them. Use a single agent for everything.
There's credible research supporting this instinct. In 2025, researchers published "Rethinking the Value of Multi-Agent Workflow" on OpenReview, testing single well-prompted agents against multi-agent workflows across seven benchmarks spanning coding, math, question-answering, and planning tasks. The single agent matched or beat the multi-agent system on every single benchmark — with better efficiency from KV cache reuse.8"Rethinking the Value of Multi-Agent Workflow." OpenReview, 2025.
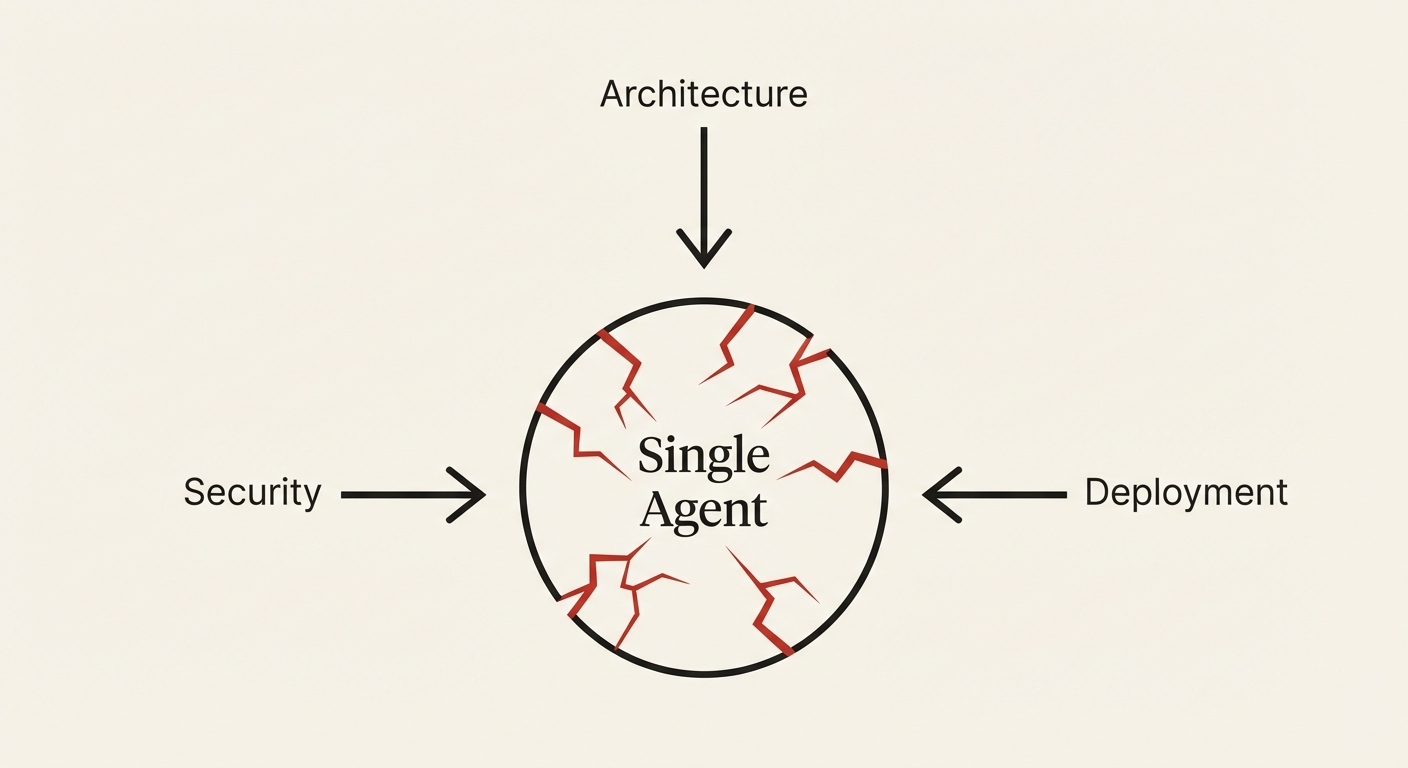
But single agents hit capability ceilings. An agent configured for implementation — with code-writing tools, test runners, and file access — can't simultaneously hold the architectural context needed for system design, the adversarial mindset needed for security review, and the operational knowledge needed for deployment configuration. These require different tools, different prompts, different perspectives. For the same reason a single microservice can't be your entire backend — not because it's lazy, but because competence doesn't scale across domains.
The compound unreliability problem doesn't mean "don't compose agents." It means agent composition requires engineering discipline that doesn't exist yet.
You've spent your entire career composing certainties.
Now you're composing probabilities.

Most engineering teams evaluate agent accuracy per-step — "our code agent is 90% accurate." They never multiply across the pipeline. This diagnostic forces the multiplication. The results are usually sobering. Run this against your current agent workflow before your next architecture review.
// CALCULATE END-TO-END RELIABILITY
pipeline_steps =
per_step_reliability = %
end_to_end = per_step ^ pipeline_steps = %
acceptable_threshold = %
// If end_to_end < acceptable_threshold:
// → Add verification loops (Ch 10)
// → Reduce pipeline_steps (AGENT Principle N)
// → Add canary checks at each boundary (Ch 13)